반응형
안녕하세요? 수구리입니다.
제가 이번에 빅분기 필기시험을 준비중인데요..
공부를 하다가 정말 헷갈리기도 하고 한번에 외우고 싶어서 정리를 하게 되었습니다.
시험이 얼마 남지 않아서 포스팅에 신경을 못쓰고 있네요 ㅠ
혼동 행렬?
혼동 행렬은 Confusion Matrix 라고 하며 분석 모델에서 구한 분류의 예측 범주와 데이터의 실제 분류 범주를 교차 표 형태로 정리한 행렬입니다.
혼동 행렬 쉽게 이해하기
우선 혼동 행렬이란 아래와 같은 형태입니다.
| - | 예측 범주 값(Predicted Condition) | ||
| Predicted Positive | Predicted Negative | ||
| 실제 범주 값 (Actual Condition) |
Actual Positive | True Positive (TP) | False Negative (FN) |
| Actual Negative | False Positive (FP) | True Negative (TN) | |
우선 위의 형태를 한번에 외우면 정말 좋겠지만..
시간을 절약해보자!
1단계. 실제값과 예측값이 동일하면 T, 아니면 F 로 표시
| - | 예측값 | ||
| Positive | Negative | ||
| 실제값 | Positive | T | F |
| Negative | F | T | |
2단계. Positive면 P를 붙이고 Negative면 N을 붙이자
| - | 예측값 | ||
| Positive | Negative | ||
| 실제값 | Positive | TP | FN |
| Negative | FP | TN | |
이렇게하면 굳이 외우지 않아도 금방 혼동 행렬을 떠올릴 수 있다!
※ 실제 범주값과 예측 범주값의 위치가 바뀔 수 있음! 문제를 자세히 보자.
혼동 행렬을 이용한 분류 모형의 평가지표
정확도

- 실제 분류 범주를 정확하게 예측한 비율
- 전체 예측에서 참 긍정(TP)와 참 부정(TN)이 차지하는 비율
참 긍정률 (=재현율, 민감도)

- 실제값이 '긍정'인 범주 중에서 '긍정'으로 올바르게 예측(TP)한 비율
- Hit Rate라고도 부름
정밀도
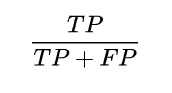
- '긍정'으로 예측한 비율 중에서 실제로 '긍정'(TP) 인 비율
F1 - Measure (F1 - Score)
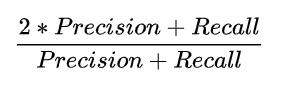
- 정밀도(Precision)와 민감도(Recall)을 하나로 합한 성능평가 지표
- 0 ~ 1 사이의 값을 가진다.
- 정밀도와 민감도 모두 크면 F1 점수가 크다.
[ 평가지표 공식 암기 Tip ]
위의 혼동 행렬 표에서 정확도 같은 경우는 모든 값을 더해주고 대각선에 있는 값 (TP, TN)이라고 유추를 할 수 있지만
나머지 공식 같은 경우는 아래의 그림과 같이 외웠습니다!

빨간색 : 정밀도를 계산하기 위해
파란색 : 참 긍정도(재현율, 민감도)를 계산하기 위해
초록색 : 특이도를 계산하기 위해
이런식으로 색깔별로 영역을 나눈 친구들의 합이 분모로 가게되고,
정밀도와 참 긍정도의 분자는 TP값,
특이도의 분자는 TN값 즉, 분자는 T가 들어간 값으로 암기했습니다.
더 어려워보이나요..?
하지만 위에서 설명했다시피 문제에서는 실제값과 예측값의 위치가 바뀌어서 나올 수 있으므로 주의!!
※ 참고 ※
만약, F1- score를 구하기 전에, 정밀도와 재현율이 같다면
F1 - score의 결과도 결국에 같아진다!
ROC 곡선

- ROC 곡선의 x축 : 거짓 긍정률 (FP Rate)
- ROC 곡선의 y축 : 참 긍정률 (TP Rate)
- 이를 시각화 한 그래프이다.
ROC 곡선의 특징
- 그래프가 좌측 상단으로 가까이 갈수록 분류 성능이 우수함
- 거짓 긍정률과 참 긍정률은 대체로 비례한다는 것을 알 수 있다.
- ROC 곡선 아래의 면적을 모형의 평가지표로 삼는 AUC를 사용하여 진단의 정확도를 측정한다.
- AUC의 값은 항상 0.5 ~ 1 사이의 값을 가지며 1에 가까울 수록 좋은 모형임
반응형
'🎁 자격증 > 빅데이터처리기사' 카테고리의 다른 글
| [ 빅분기 Daily 문제 정리 ] (2) | 2021.10.01 |
|---|